Hackathon - AI for Oil & Gas
Dates: 10–14 November 2025 - In person at CBPF (Rio de Janeiro, Brazil)
Pitch and final jury: 20 November 2025 - during SBGF
Data Tracks
The Hackathon will feature three independent data tracks. Each registered group must choose and work on two tracks, developing solutions based on simulated datasets prepared exclusively for this competition.
Each track includes training and testing subsets:
- Training – available for development and solution adjustments.
- Testing – used exclusively for final evaluation by the jury.
Nuclear Magnetic Resonance (NMR)
Description:
The challenge consists of developing artificial intelligence models capable of predicting the proportions of fluids (oil and water) from magnetic relaxation curves of the perpendicular component of magnetization, M_⊥ (t), obtained by Nuclear Magnetic Resonance (NMR), specifically CPMG sequences. This is an application of machine learning models/algorithms in which the inputs are time series representing the evolution of magnetization over time, and the target output is the corresponding oil concentration in the digital rock for each input M_⊥ (t). The input curves M_⊥ (t) were simulated computationally in digital rocks and come with white noise at different signal-to-noise ratio levels. The expected result contributes to the petrophysical characterization of reservoirs, helping estimate the proportions of fluids of interest with different petrophysical parameters.
Data structure:
- Simulation based on digital rocks generated by packing rigid spheres (radii from 3 μm to 21 μm) in a 100 μm cube.
- Average porosity of ~0.26.
- CPMG sequences with echo spacing of 500 μs and surface relaxivity of 50 μm.
- Oil proportion ranging from 15% to 80%.
- Tabular format (train and test), containing:
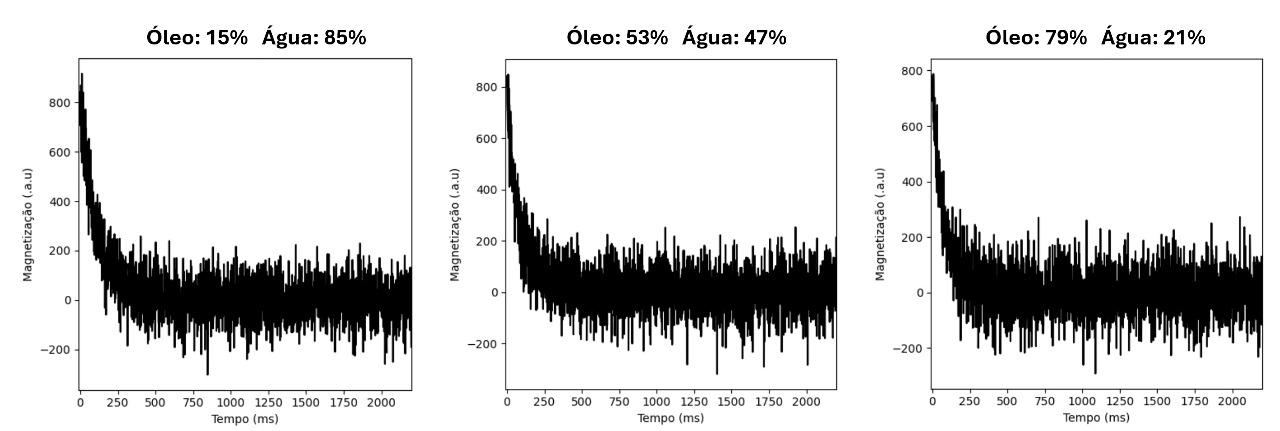
- Time series of the M⊥(t) curve (input).
- Oil–water proportion (output).
Petrographic slides
Description:
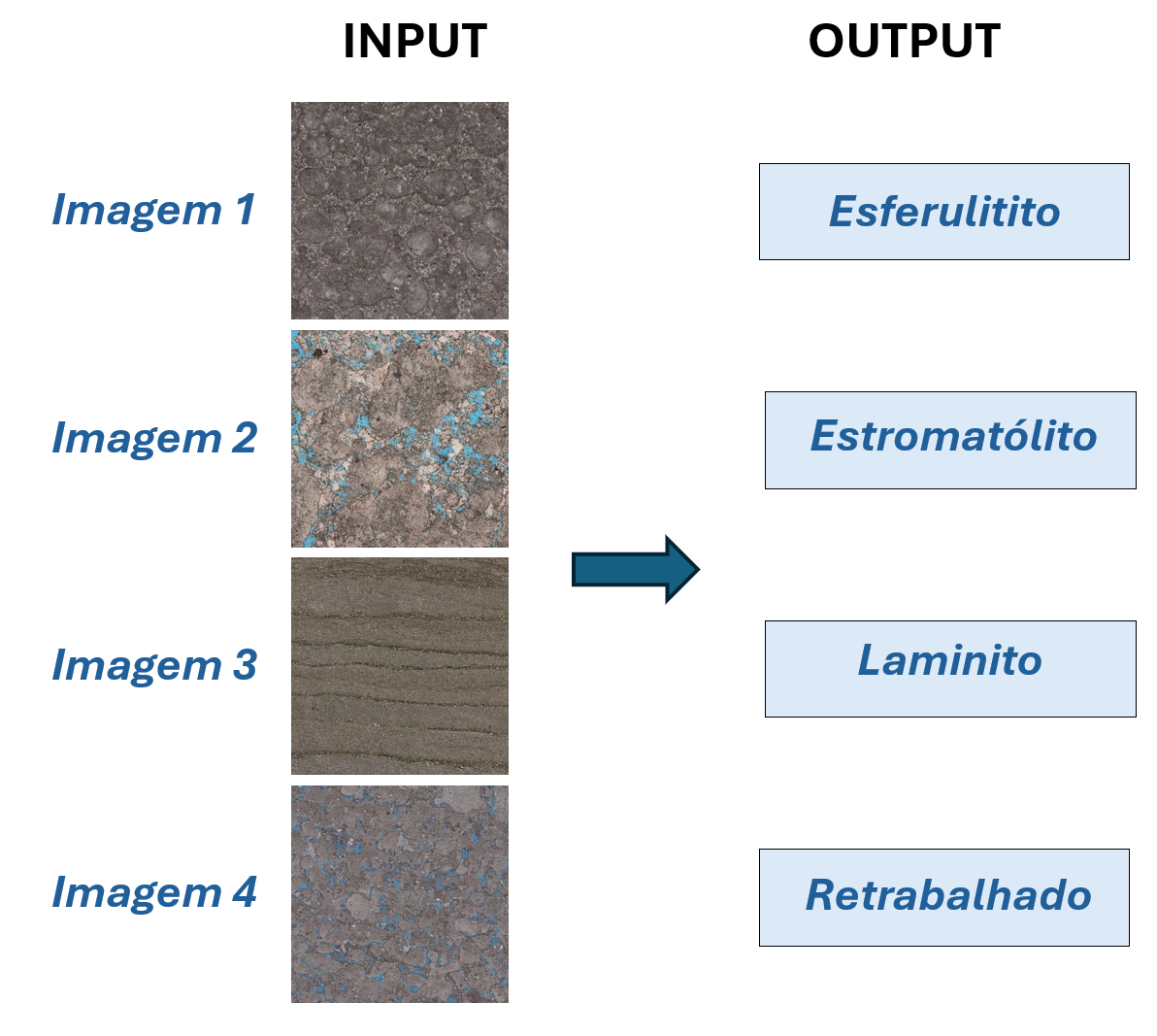
Develop machine learning models capable of automatically classifying the lithology of petrographic slides of Brazilian pre-salt carbonate rocks. The goal is to increase the efficiency and standardization of petrographic analysis in complex geological contexts.
Data structure:
- Data type: synthetic thin-section image crops of carbonate rocks.
- Quantity: 800 images.
- Resolution: 256 × 256 pixels.
- Color format: three channels (RGB).
- Lithological classes: spherulitite, stromatolite, laminite, and reworked.
- Characteristics: preserve textures and structures of the original slides.
- Data format: (2 folders train and test with .png images).
Seismic
Description:
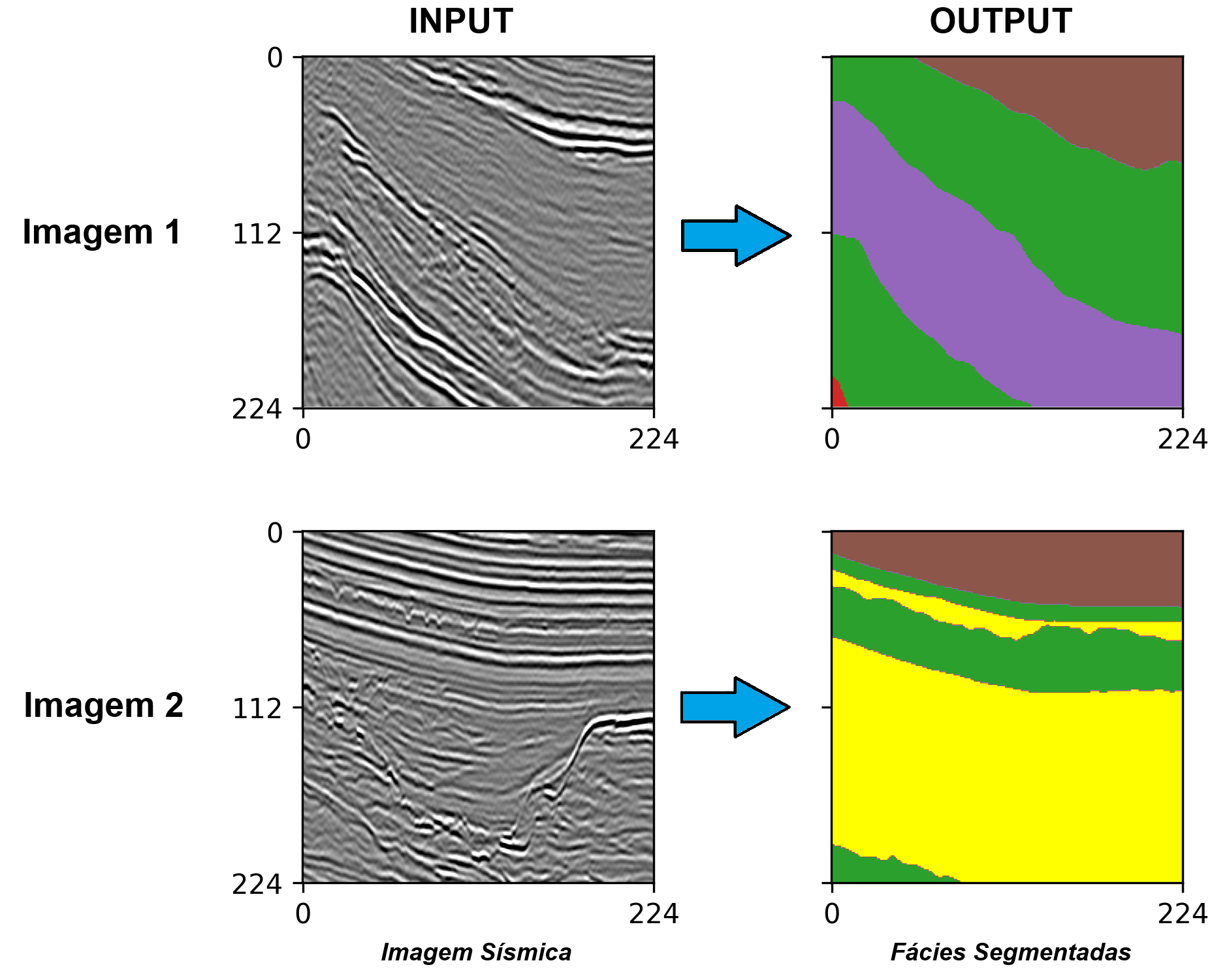
Develop machine learning models capable of automatically segmenting seismic facies. The goal is to support the automation of seismic interpretation, contributing to building more accurate geological models and accelerating exploration processes.
Data structure
- Data type: fragments (patches) of seismic images extracted from a 3D volume.
- Quantity: approximately 25,000 patches, generated on a regular grid with minimal overlap.
- Resolution: 224 × 224 pixels.
- Format: grayscale (single channel).
- Labels: pixel-by-pixel segmented masks indicating the different seismic facies present in each fragment.
- Characteristics: the dataset includes six facies classes, representing different depositional systems.
- File format: divided into training and test sets. Each set is provided in two .npy files: one containing the seismic images and another containing the corresponding masks with segmented facies.
NoteAll patches were generated from a public-domain seismic volume (New Zealand). The facies interpretation was carried out by Chevron (under Creative Commons CC-BY-SA license).
- The seismic data are publicly available and provided by New Zealand Petroleum and Minerals (NZPM). See https://www.nzpam.govt.nz/maps-geoscience/exploration-database/
- The associated labels, Geological model labeled of Parihaka seismic data for machine learning, by Chevron U.S.A. Inc., are licensed under CC BY-SA 4.0. See https://creativecommons.org/licenses/by-sa/4.0/
Note:
The datasets used in this hackathon are for the exclusive use of the Brazilian Center for Research in Physics (CBPF) and were prepared specifically for this competition. Their use is permitted only during the event.
The solutions developed will remain the intellectual property of the respective authors, who may keep and use the trained models after the hackathon. However, it is prohibited to share, reproduce, or redistribute the datasets outside the context of this competition.
By completing registration, the participant declares awareness and agreement with this rule, committing to fully comply with it.